概述
使用Redis之时有一个最重要的问题: 为什么Redis使用单进程依然可以达到很高的性能?
那么此问题可以拆解为两个。
Redis为什么采用单进程?
首先,虽说我们一直强调Redis是单线程,但只有在执行读写操作时是由单个线程进行操作,而其他的如持久化、集群数据同步等相关操作时,一般都会另外开启子线程进行操作。
那么为什么要单线程负责读写呢?这是因为要考虑Redis所处的高并发业务场景。一般我们为了在高并发场景下保证数据集的正确性和完整性,在每次读写操作时都会采用加锁的策略,虽然确实是多个线程在执行指令,但在Redis的业务场景下将会有大部分的线程处于等待锁的状态下。再加上多线程下的线程切换带来的性能消耗的相互影响下,多线程的性能反倒不如使用单线程进行操作。
Redis为什么快?
实际上有两个原因,其一是Redis本身是基于内存进行操作,速度快是必然的。其二是Redis在网络IO操作时采用了多路复用机制,即非阻塞IO。
总的来说,Redis性能的主要点有两个,其一是通过网络将对应的请求数据传输到Redis,其后Redis根据数据(指令)进行读写操作。由前述可知,对于读写操作而言Redis的速度是极快的,因此主要的时间点就是网络数据到Redis这段时间了。因此使用多路复用机制可以同时处理多个IO,那么Redis在"等待"对应的数据发送完毕前,可以优先去执行其他的请求。
因此,这样的Redis在两个时间点都优化到了最佳,也就成就了它的快。
基础类型
Redis主要提供了五种基本的数据类型,即string、hash、list、set、zset(有序集合)。而此五者的类型底层又有不同的编码方式,因此首先要明白它们是什么,如何实现,及为什么使用。
编码方式
以SDS结构为基础的embstr与raw
SDS结构: 结构体包含len长度与free(剩余空间数)。之所以使用SDS而非char的缘故有两个,其一为Redis高频率的会获取len长度与剩余空间数,而char的对应操作是O(n)。其二是因为Redis使用SDS可以防止内存溢出。
embstr在其底层分配一块内存,其中含有redisObject与SDS结构。而raw的底层则是将redisObject与SDS去做划分。
embstr与raw的结构有什么区别呢?首先embstr是将redisObject与SDS结构连接为一体的结构,而raw则是将此两者分开划为两块内存空间。
猜测:
短串在修改的时候直接删除并重新分配内存的性能远大于进行惰性空间释放。而长串则是使用惰性空间释放更优(惰性空间释放: 当字符串变短后,将未使用的空间计入到free属性之中,而非直接进行回收内存)。
ziplist
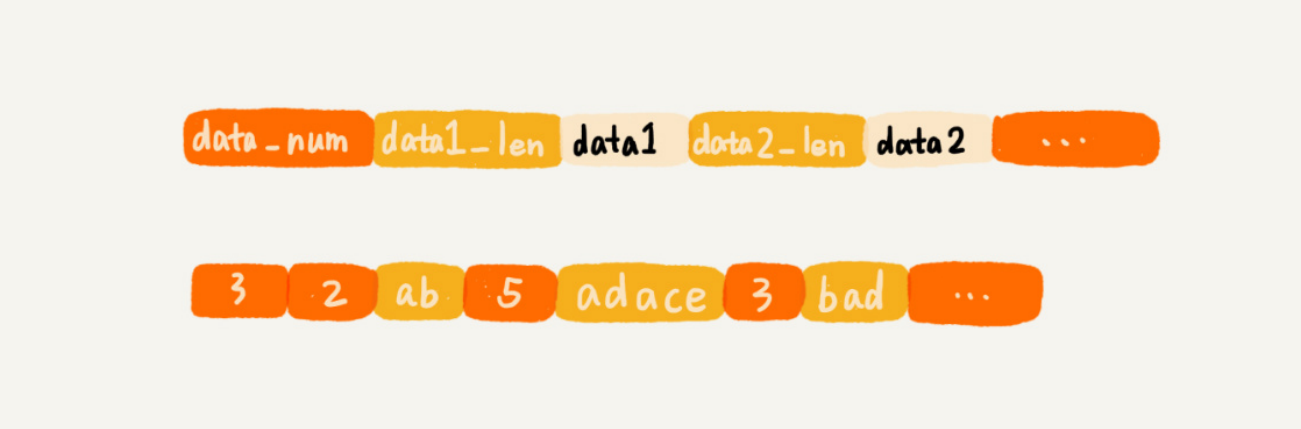
简单来讲,ziplist本质亦是在内存中连续的结构,如同数组。但其在设计的时候与数组有些区别,主要相较更省内存空间。一般在使用数组时,无论对应数据使用了多少的内存空间,都会使用数组的对应类型的空间大小。
例如创建一个大小为8的int数组,那么无论它存储的空间到底利用多少,也必须要使用32字节的空间,而ziplist则不然。
那么这时就衍生一个问题: 为什么根据数据量的多少而选择两种不同的编码方式呢?
显然,使用ziplist占用一块连续的内存,在数据量小时可以有效的节省空间。但当数据量增多后进行修改反而因为连续内存需要重新分配空间的效率而显得低效,因此转为链表实现。
quicklist
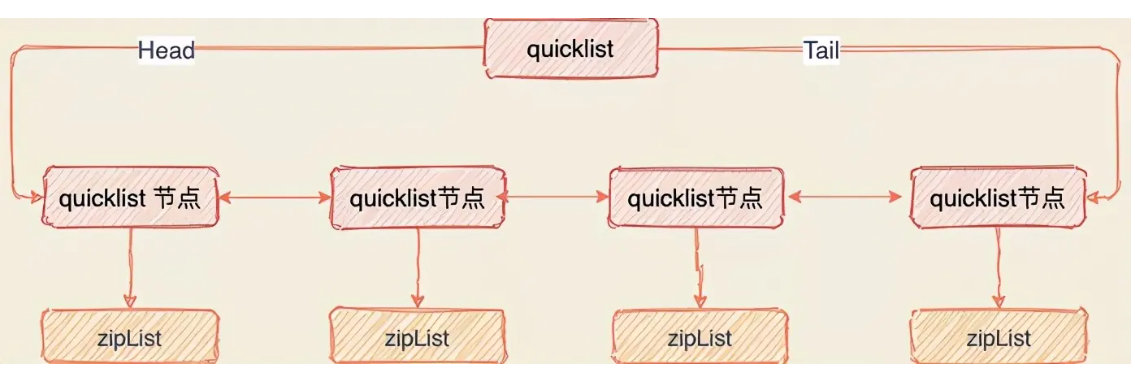
quicklist为ziplist的升级。前述可知,ziplist当数据量过大时便会由于连续空间而影响性能。于是quicklist设计成一组ziplist为节点的双向链表。将linkedlist与ziplist的特性相结合,也就成了quicklist。
skiplist
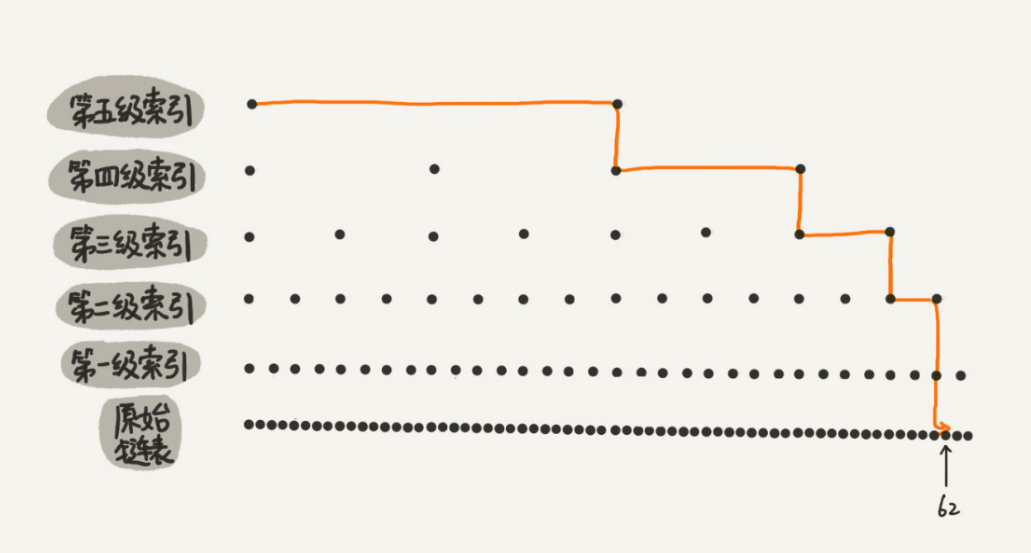
跳表本质上是对链表的一种升级,在原始链表的基础上添加索引层,这样便可以更快速的进行读写。之前没有了解过这个结构,故此简单记录。
string: 字符串
显然,string是最常用的一种格式,它可以存储字符串亦可以是整数及序列化后的对象。
其底层有着三种数据结构,如采用整数类型,那么其对应的数据结构是long型。而如果是字符串且不超过44字节时,采用embstr类型。而如果超过44字节,则raw类型。
hash: 字典
hash本质为一个键值对结构,其底层编码为ziplist和hashtable。在单个键值对的键与值均小于64字节,且键值对个数少于512个时将采用ziplist实现。其他场景下使用hashtable。
对于hashtable,Redis采用了名为MurmurHash2的哈希算法,其运行速度快且随机性亦很好。对于哈希冲突问题使用链表法解决。处理之外Redis还支持动态扩容与缩容。
list: 列表
其中list主要的特性是提供了在左右两边加入与弹出的指令,以此可以轻松的实现栈和队列。
其底层分为两个版本,其在3.2版本前在单个数据小于64字节,且数据个数少于512个时将采用ziplist实现,反之使用linkedList(双向循环链表)实现。
而在3.2版本后则直接使用quickList实现。
set: 集合
对于集合这种数据结构是用来存储一组不重复的数据,且可以对集合之间可以进行交集、差集、并集操作。其底层分为两种情况。其一,如果存储的数据均是整数,且数量不超过512个,那么采用intset(有序数组),反之采用hashtable。
zset: 有序集合
zset作为有序集合,与set最大的区别是其不仅存储value,还存在一个"score"属性,其作为所对应顺序的依据。与其他类型一样,拥有两种实现方式。在所有数据均小于64字节,且数量小于128的时候使用ziplist实现。而其他场景下采用skiplist。
拓展类型
实际上Redis中的拓展类型在没有需求了解其底层原理的情况下,是非常简单的。因此此处仅留下简单的笔记。
pipeline
Redis由于其操作都基于内存,因此它的性能瓶颈往往不在命令执行,而在于网络传输。因此当涉及到要一次性提交多个命令的需求时,理应选择pipeline进行提交。
但要记得Redis是单线程的,如果提交的命令时间过长,那么其他的操作将被阻塞!

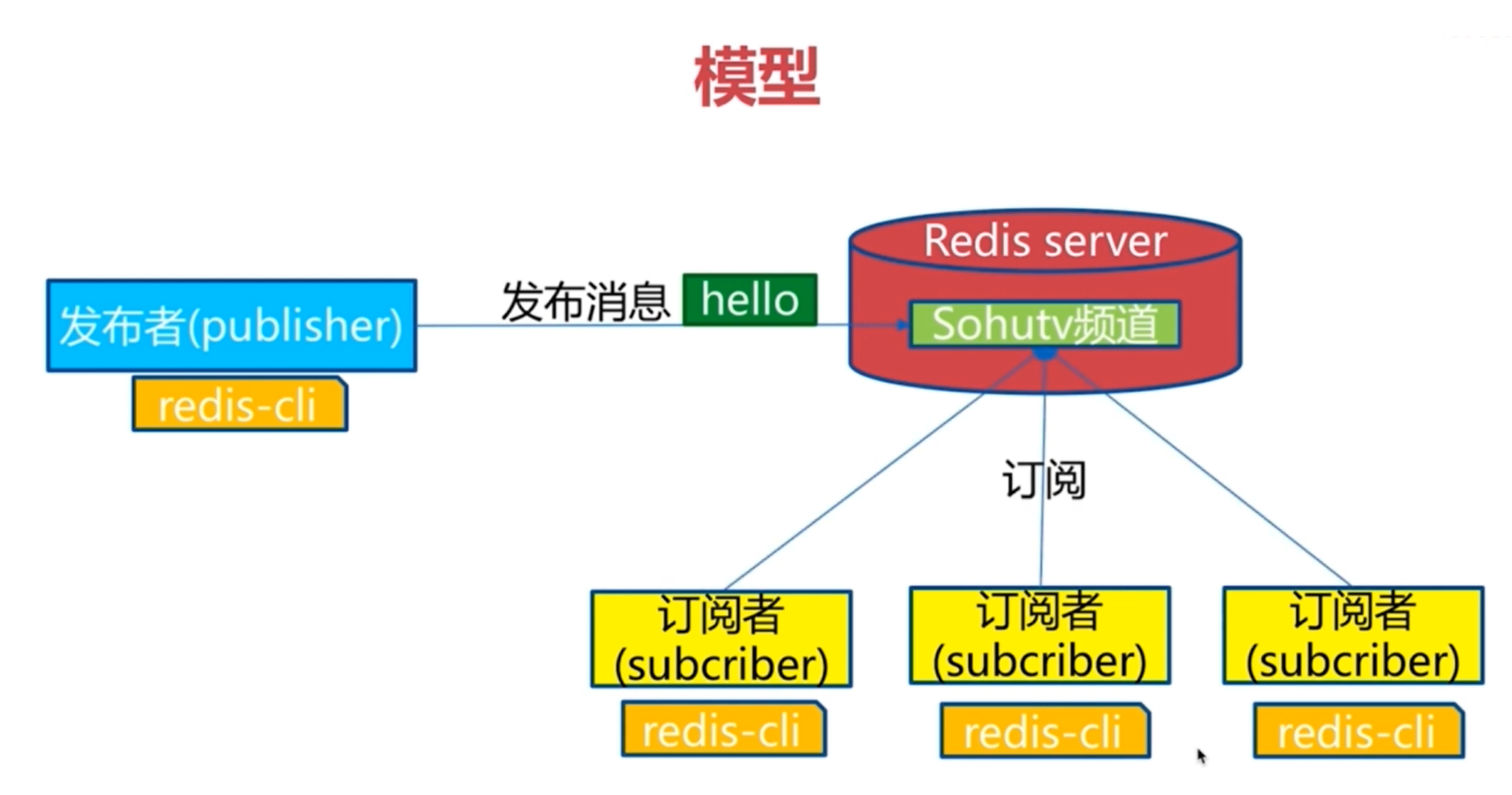
订阅发布
Redis实现了一个简单的订阅发布系统,其中设计了: 发布者、订阅者、频道的一个模型。其中发送者通过频道发送信息,其后频道的信息会自动广播给所有的订阅者。


hyperloglog
一般作为对一个集合不重复的个数进行快速计算,如某篇文章被用户访问的统计。

笔记留存

