概述
主要原因是因为很快就要参加云计算的技能大赛。原本以为是明年三月份,结果定在了十月初的样子,囫囵吞枣的把Hadoop相关的过了一遍。
Hadoop 分布式环境是组员给搭建的,就不再纂述。(其实是因为我搭半天懒得学了2333...
所谓 HDFS 是指一套分布式存储系统,主要目的是为了能够容下更多的数据。常理来看,一台电脑的容量总是有限,而如果这台电脑可以无线增加容量,便可以达到 "无限" 的容量。简单来说,HDFS 就是这样一套存储系统。
而 MapReducer 则是计算数据的一个框架,其实应该分为两个单词: Mapper 和 Reducer 。Mapper 是指对数据的映射,而 Reducer则是对映射(Mapper)到的数据进行整理、输出。
配置
我们需要引入:hadoop-common 、hadoop-hdfs 、hdoop-client 三个包。
需要注意的是,这些版本最好高于你所安装的版本,但也不要太高,我所安装的 Hadoop 是2.7.6,而包的版本都是2.8。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.0</version>
</dependency>
但配置这些远远是不够的,我们虽然大部分操作都是基于远程调用,但有些操作 Hadoop 依然需要你将其下载在本地,并配置环境变量,以及 winutils , 否则会报错!这里就不在纂述过程。
HDFS
首先我们需要去获得 HDFS 的基本操作对象 FileSystem 。首先第一个参数为你的 HDFS 运行在那个端口。然后是第二个参数: Configuration 可以通过它去设置 Hadoop 的默认设置,不过这里没有用到。
其次,第三个参数代表你使用的用户名,如果用户名不具有操作权限,则报错。
@Before
public void start() throws URISyntaxException, IOException, InterruptedException {
Configuration configuration = new Configuration();
fileSystem = FileSystem.get(new URI("hdfs://192.168.100.10:9000")
, configuration, "root");
}
创建文件
@Test
public void create() throws IOException {
Path path = new Path("/WordCount/hello1.txt");
FSDataOutputStream out = fileSystem.create(path);
out.writeUTF("hello word hello");
out.flush();
}
获取路径下的所有文件
/**
* 获取路径下的所有文件
* @throws IOException
*/
@Test
public void listFiles() throws IOException {
Path path = new Path("/hdfsapi/test/");
FileStatus[] files = fileSystem.listStatus(path);
//递归显示
//FileStatus[] files = fileSystem.listFiles(path,true);
for (FileStatus file : files) {
System.out.println(file.getPath());
}
}
上传大文件:带进度线程
/**
* 上传大文件:带进度显示
* @throws IOException
*/
@Test
public void copyFormLocalBigFile() throws IOException {
InputStream in = new BufferedInputStream(new FileInputStream(new File("C:\\Users\\Administrator\\Desktop\\jdk-8u181-linux-x64.tar.gz")));
Path path = new Path("/hdfsapi/test/jdk.tar.gz");
FSDataOutputStream out = fileSystem.create(path, new Progressable() {
public void progress() {
System.out.println(".");
}
});
IOUtils.copyBytes(in,out,4096);
}
方法该有的都有,大多相似,仅记录到此。
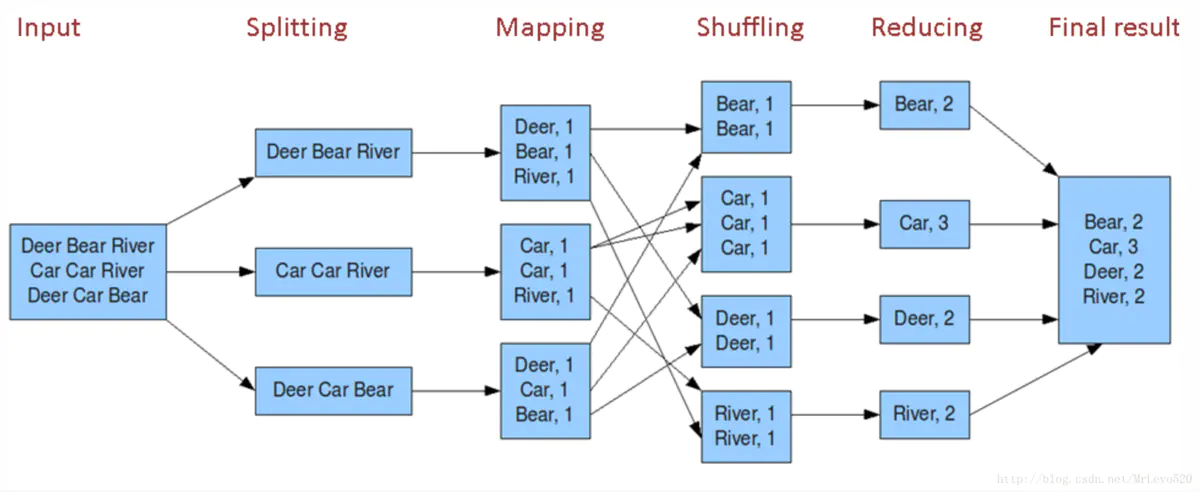
使用 HDFS 编写词频计数
简单的来说,就是去记录文本文件中,一个单词的出现次数。以下代码涉及到:获取文件列表、创建文件。
public static void main(String[] args) throws Exception {
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.100.10:9000"),
new Configuration(), "root");
Path path = new Path("/WordCount/");
RemoteIterator<LocatedFileStatus> files = fs.listFiles(path, false);
HashMap<String, Integer> result = new HashMap<String, Integer>();
while (files.hasNext()) {
LocatedFileStatus file = files.next();
FSDataInputStream in = fs.open(file.getPath());
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line = "";
while ((line = reader.readLine()) != null) {
String[] split = line.split(" ");
for (String s : split) {
s = s.trim();
if (result.get(s) != null){
result.put(s,result.get(s) + 1);
}else{
result.put(s,1);
}
}
}
in.close();
reader.close();
}
FSDataOutputStream out = fs.create(new Path("/WordCount/out.txt"));
out.writeUTF(result.toString());
out.flush();
}
MapReducer
在概述中我们就说到,我们 MapReducer 是指映射和整理两个功能。那么当我们获得一个数据集之时,则要先创建对其的映射。这里我们仍然使用 HDFS 中词频统计的样例。
Mapper
我们需要创建一个继承于 Mapper(org.apache.hadoop.mapreduce.Mapper) 的类,并实现其 map 方法。我们需要声明四个类型,前两者代表我们拿的数据的行数与内容。
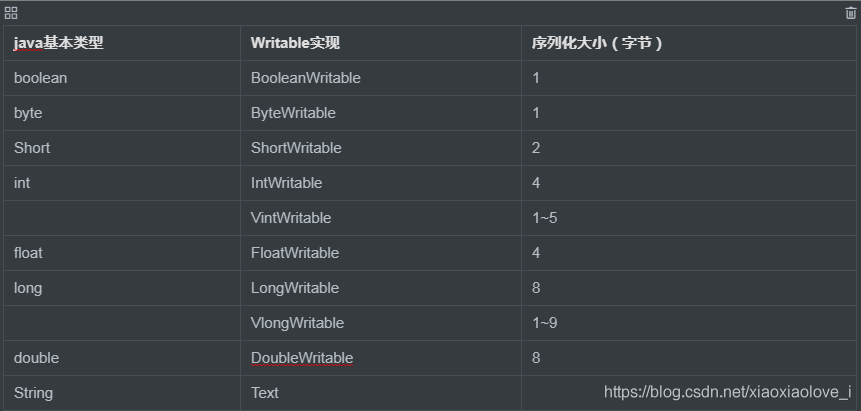
简单的说,我们拿到一个数据文本,一般是采用以一行为分割依据,那么第一个参数代表这一行的首字符位置,其次则是这一行的内容。那么为什么本该是 Long 的类型要写成 LongWritable 呢?因为这些自定义的类型本身拥有序列号以及反序列化的特性。
而后两个参数则是指,当我们映射完毕之后输出的 map 的类型,这里需要知道,我们的数据一般是采用 map 形式进行输出!
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>
map 方法其中有三个参数,第一个是指当前行的首字母的位置,也就是从 0 位到当前位置的偏移值。其二,当前行的内容,其三,输出 map 的对象。我们在前面说,我们映射完的对象是一个 map 形式的。而我们需要使用 context 对象进行写入这个 map。
因此代码就很简洁明了,我们将一行数据以空格为分隔符去分割,然后我们得到一系列的字母,并赋其值计次为1。
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String word : words) {
context.write(new Text(word.trim()),new IntWritable(1));
}
}
Reduce
同样的,我们需要创建一个继承于 Reducer(org.apache.hadoop.mapreduce.Reducer) 的类。也是需要声明四个类型,前两者为接收到的映射类型,后两者为整理完毕输出的类型。
public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable>
实现其方法 reduce。我们得到三个参数,第一个很显然是之前我们在 mapper 中写入的key,而第二个参数倒不是 value,而是value的一个迭代对象,它包含了数据中所有key值为当前key指的 value。为什么呢? 因为在执行 Reduce 整理操作之前实际上经历了 shuffing 层,该层会将其一个个的进行对应,然后发送到 Reduce 层。
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Iterator<IntWritable> iterator = values.iterator();
int count = 0;
while(iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key,new IntWritable(count));
}
job(开始任务)
当完成以上任务的时候,我们就只剩下去提交任务了。
//设置当前用户为root,与 HDFS中 FileSystem.get() 方法中我们输入的用户名功能相同。
System.setProperty("HADOOP_USER_NAME","root");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.100.10:9000");
//创建提交任务的对象
Job job = Job.getInstance(configuration);
//设置Jab在那个类执行
job.setJarByClass(WordCountApp.class);
//设置Mapper类
job.setMapperClass(WordCountMapper.class);
//设置Reduce类
job.setReducerClass(WordCountReducer.class);
//设置Mapper输出的key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Mapper结束后的Combiner操作,对Mapper做一次聚合,这样可以减少IO并提升性能,然后在shuffle层进行整理。
//但是在某些计算任务的时候使用它则会出现错误,如:求平均值。
job.setCombinerClass(WordCountReducer.class);
//设置Reduce输出的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//作业输出和输入的路径
FileInputFormat.setInputPaths(job,new Path("/WordCount/"));
FileOutputFormat.setOutputPath(job,new Path("/WordCount/out1.txt"));
//提交任务
boolean result = job.waitForCompletion(true);
System.out.println(result);
实现复杂类型
当我们将处理复杂的数据集的时候,我们不可能通过 Hadoop 提供的数据类型达到我们的目的,因此我们需要自定义一个类型。
我们需要实现 Writable(org.apache.hadoop.io.Writable)接口,并分别实现 write 方法和 readFields 方法。从名称可以看出,二者分别是读取和写入。
public class Access implements Writable {
private String phone;
private long up;
private long down;
private long sum;
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeLong(up);
out.writeLong(down);
out.writeLong(sum);
}
public void readFields(DataInput in) throws IOException {
this.phone = in.readUTF();
this.up = in.readLong();
this.down = in.readLong();
this.sum = in.readLong();
}
这样我们就可以复杂类型了。
本页的评论功能已关闭