前述
众所周知MySQL对于底层的存储逻辑都由选择的存储引擎所决定,自MySQL5.5以后默认的存储引擎编为InnoDB,因此对于MySQL的存储结构学习自然便是围绕着InnoDB。不过其后仍有必要去了解常用的存储引擎相互之间有何之区别。
首先InnoDB下的表是基于聚簇索引而建立。何为聚簇索引?即数据便是索引,索引便是记录。
那么何为索引?索引有何用?
之所以有索引这个概念是因为它可以优化我们的检索速度。
对于检索数据而言,我们的第一个想法便是自前往后遍历就是,这样的时间复杂度是O(n)。那么是否有优化的空间呢?自然,我们可以想到将那些数据转换为某种适合检索的数据结构。
但如果沿此思路,当我们在检索数据的时候需要先从磁盘中把数据读出来,再对其构造出结构,如果数据集很是庞大,这将需要耗费大量的时间做预处理,实属不妥。因此产生了一种思路,我们以某种数据结构为基础,仅记录下每条数据的主键以及对应文件偏移值,这样仅需要以这些数据为载体进行加载便好。这便是最简陋的主键索引了。 除此之外亦可以对行内的其他列为基础去构建索引。
那么整理一下语言:什么是索引?将表中某一列的值单独抽离变为指向对应行的标志,并将表中所有的标志以某种能使其查询速度更优的结构供以快速查询,以此避免从头往后全表查询。而与前述所说的索引不同,InnoDB的索引并非记录文件的偏移值,根据聚簇索引的定义是直接将数据与结构为一体。这样看起来好像有些本末倒置,不过并非如此,沿此博文后续将明了。
以此产生了几个问题需要答案:
- InnoDB使用什么数据结构?
- InnoDB为何不使用XX结构?
- InnoDB直接使用聚簇索引为基础,那么检索时如何在不消耗性能的情况下加载索引?
InnoDB采用的数据结构: B+Tree
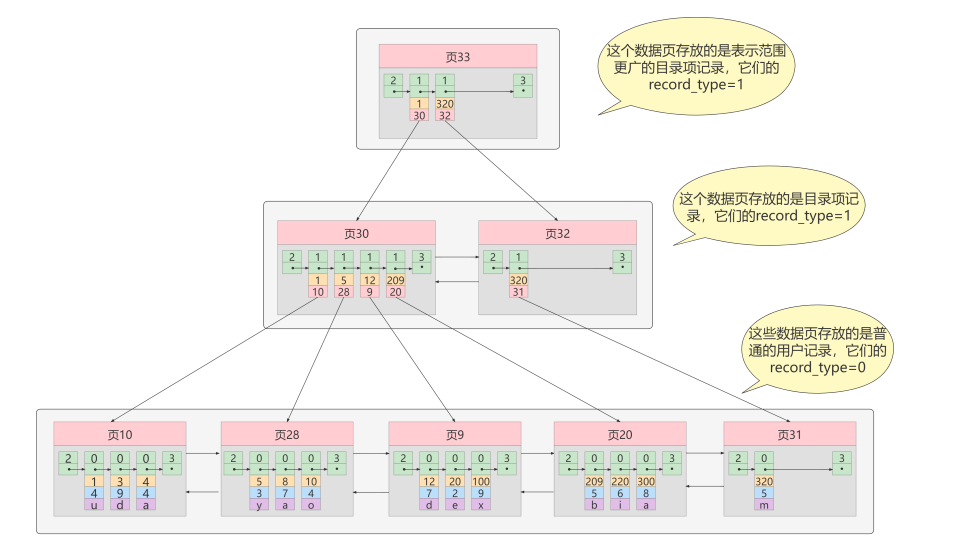
如标题所示,InnoDB在存储时所采用的数据结构名为B+Tree,其可溯源到B-Tree(并非是减号),本质为一个多路平衡的二叉搜索树。不过B+Tree在它的基础上做了一些改变。
首先,它的基本单位为数据页(即结点),一个数据页能够存储16kb的数据,而数据以数据表中的每行数据为单位,每个数据之间以单向链表连接彼此。并且其中数据具有有序化,而有序化是根据索引所绑定的列来构建。
而数据页之间以双向链表连接彼此,不同的数据页中的记录分为不同的类型。最主要的类型区别为,有的称其为聚簇索引,存储的是数据,而有的存储的是供以快速访问到聚簇索引(数据)的目录项,即为非聚簇索引,而判定的条件是结点中的record_type属性,其中叶子节点配置均为0,而其他结点均为1。
意思就是说,在B+Tree之中只有叶子节点存放是数据项,而其他结点都是目录项。
而其中最重要的一个特性是,B+Tree中叶子结点的数据均是有序的,排序的原则根据索引对应的列。
构建B+Tree流程
每当某个表创建一个索引时,会为这个索引创建一个仅拥有根节点的B+Tree,也就是说在一开始的时候这个索引表既没有数据项也没有目录项。
随后当开始加入记录时会存入到根节点之中。当根节点的可用空间用完时,会把根节点的所有记录复制到一个新分配的页之中(命名为a页),其后会再创建一个页(命名为b页),随后判断后来的记录根据其顺序判断是插入到a或b之中。其后根节点转而升为目录项,其中的记录分别指向页a与页b。
其后的数据都亦是如此。
检索流程
综上得知了B+Tree的基本结构,那么其后便可了解它的大概检索步骤了。
首先从B+树的根节点(亦是目录项)开始,想象一个基本的二叉搜索树逐层进行查找,最终发现叶子节点(数据项)的所在位置,那么此时便将其加载到内存中,其后从数据页之中检索数据即可。
如果此时为主键索引,那么只需从数据页中遍历数据就好。但并不止如此,除了主键索引外还有二级索引以及联合索引。
二级索引
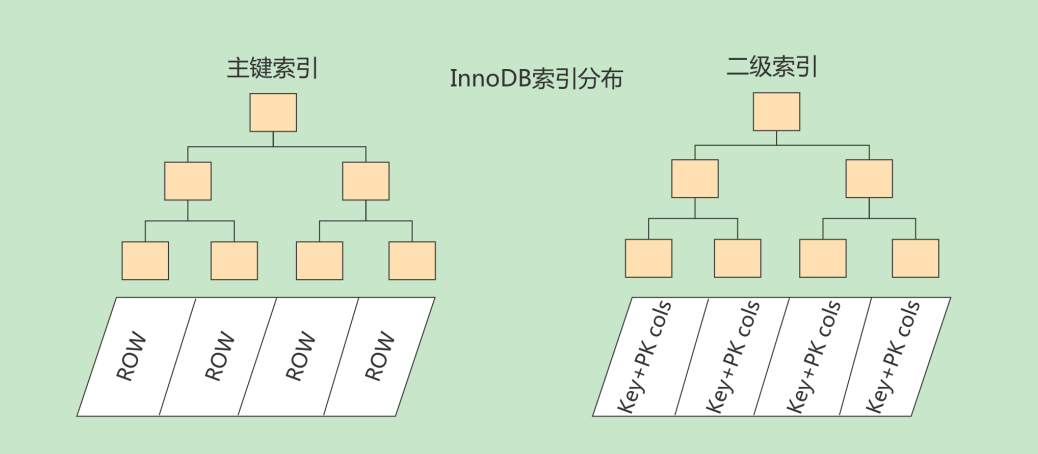
何为二级索引?一般来讲在一个表往往不止仅依靠主键进行检索数据,也可能要依靠其他的列进行检索,那么由其他列所构建的索引便称之为二级索引。
二级索引与主键索引的数据结构唯一的区别在于其数据页中存储的记录是对应列的值与主键值。那么很明显,当使用二级索引进行检索的时候,除了完成它的检索过程,还需要通过依靠其记录中的主键值进行回表操作,即通过主键值再走一遍主键索引以获取完整的数据。
联合索引
联合索引是为多个列同时构建一个索引,本质亦是二级索引。其同时以多个列的大小作为排序顺序,不过多个列的排序顺序是以对应列的建立顺序而决定。比如为 c1、c2、c3构建,那么其顺序则是先以c1进行,当c1相同的时候再以c2进行,c3亦如是。
缺点
由前述可知,B+Tree中存储的数据具备有序性,这也就意味着每次插入的记录与之前的数据是有序的还好,直接插入到某个页中,亦或重新分配页。但如果索引对应列每次插入都是几乎无序的值,那么将意味着每次插入都将导致页分裂——插入到前面的数据之中,然后将此数据往后的数据后移。
这也是对于InnoDB表一般建议使用自增ID为主键的缘故。这时突然想到以前项目中总是使用UUID作为主键ID,这便是一个严重的设计错误。不过经过查询,通过雪花算法生成的UUID具备有序性。
与其他结构的区别
// 鸽一下
再进一步的结构了解: 数据页
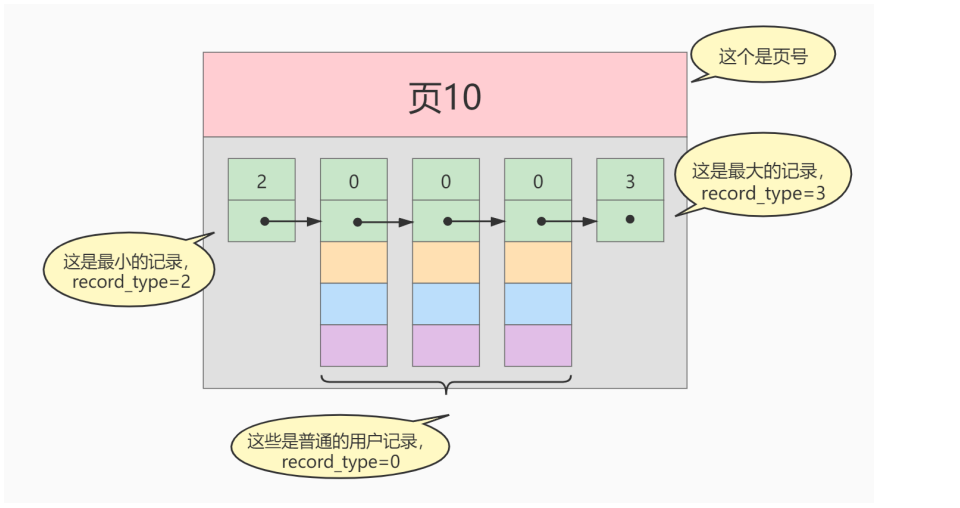
上图便是在B+tree结构图中的数据页结点,可以看出有着页号、最小记录、最大记录、以及被称之为用户记录的存储记录的地方。
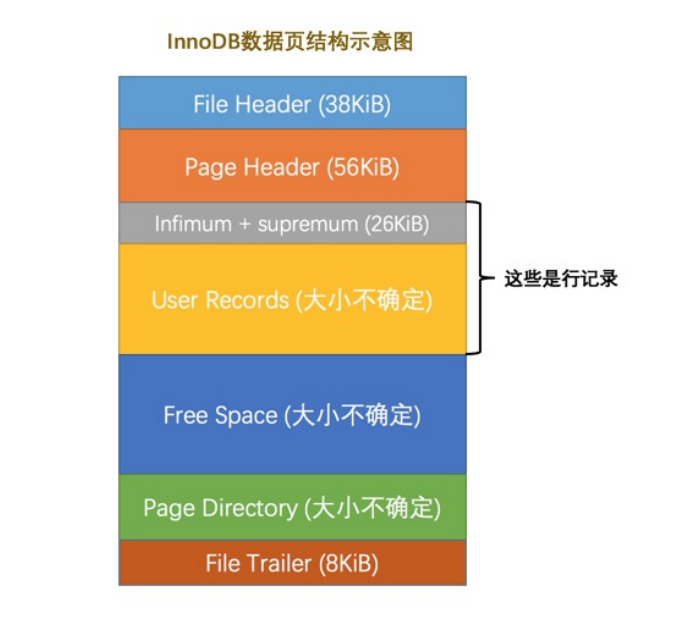
但数据页中的结构并不如图所示这样简单,为了满足各种需求,被划分为七块,主要功能如下:
- File Header 文件头,主要记录页的一些通用信息
- Page Header 页头, 主要记录数据页中的一些信息,如:「还未使用的空间最小地址」、「本页中记录的数量」、「第一个被标记为删除的记录地址」...
- Infimum + Supremum 主要代表页中的最大记录和最小记录,但其并非是一个真实存在的行记录
- User Records 用户记录,实际存储记录的空间
- Free Speace 空闲空间, 页中尚未使用的空间
- Page Directory 页面目录,可借此快速访问用户空间中的记录
- File Trailer 文件尾部,主要用来校验页的内容是否完整
File Header 与 File Trailer
File Header的主要用处在于记录当前页的相关信息,一般标记了页码、页的类型(系统页还是日志页,亦或索引页?)、又有页的前后节点,即前后页的连接地址便在File Header之中。
除以上信息外,Header存放着对页内数据的一个整体校验和,其最主要的目的在于与File Trailer中存放的校验和进行比对。假设当页在刷新到磁盘之中发生故障,那么磁盘中页的Header中存放的校验和,必然与Trailer中的校验和不同,以此便可发现问题。
而Trailer除了校验和之外,还存放着页面最后修改时对应的日志序列位置,以便后续进行恢复。
User Records 与 Free Speace
起初页中是没有用户记录的,但当第一个记录将被插入时会从空闲空间中分配出空间供以存储。即用户记录随着记录的插入会逐渐去占用空闲空间,直至空闲空间被分配完毕。
Page Directory
对页内数据以4~8个记录分为一组,随后将每组中最大的数据存入页目录数组之中,以次形成数据页的页目录。当检索到数据页的时候,仅需对页目录进行二分查找,到达对应组,随后进行遍历就好。
再再进一步的结构了解: 行格式
前面简单说了页,虽然它在树中为最小的基本单位,但在我们眼中并非如此。在我们不了解底层存储结构时,我们眼中的基本单位其实应该是行,即记录。而记录如何存储,以什么格式存储,也是有不同区别的。MySQL中常用的主要有:Compact、Dynamic、Compressed三种行格式(另有名为Redundant的行格式,但已被淘汰)。其中Dynamic是MySQL中设定为默认的存储格式。
Compact
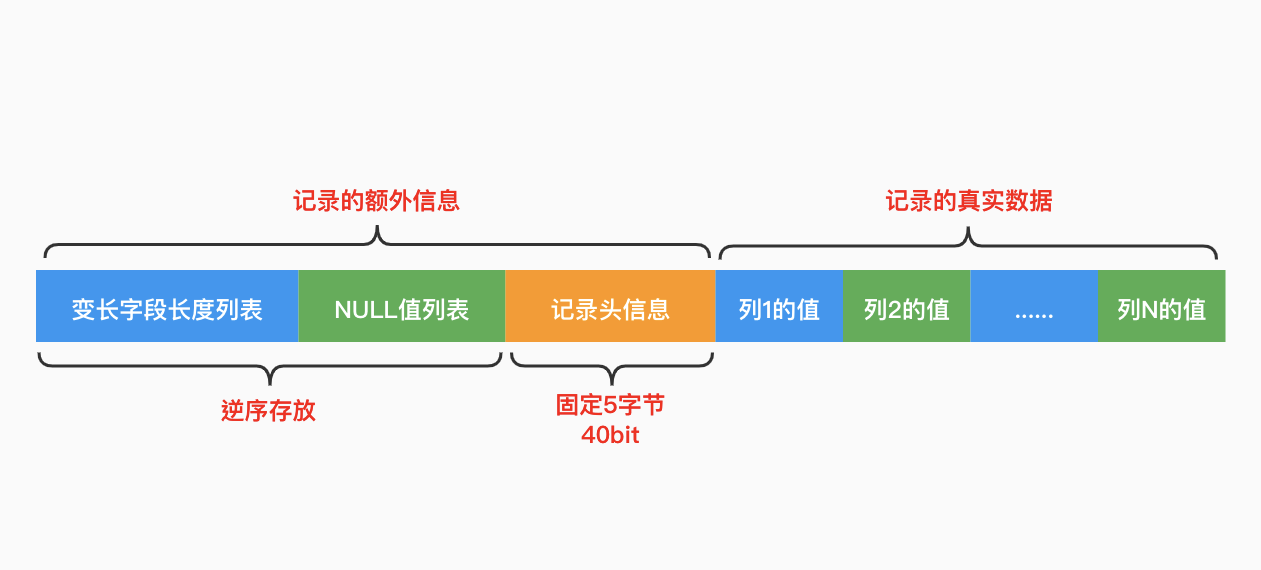
compact格式主要分为两个部分,其一是额外信息,分别是:
- 变长字段长度记录,主要记录变长类型真正使用的长度是多少
- NULL值记录,以二进制位为标记去记录那个值为NULL
- 记录头信息,一些关于「记录」的信息
其中头信息中主要的几个信息如下:
- deleted_flag 删除标记,执行delete后并不会立马从磁盘中清理,而是通过此属性进行标记,其后可以直接替换掉被标记记录的空间
- record_type 记录类型,标记其为普通记录或是Infimum记录、SuperMum记录,亦或者是目录项记录
- next_record 下一条记录的位置
- heap_no 当前记录在页面堆里的相对位置