持久化
虽说Redis一般只是将其认为是为了数据库做冗余,以缓解其压力的中间件。但随着Redis的发展,它的作用并不仅限于此了。回到整体,由于Redis的数据全部都存储在内存之中,倘若Redis突然宕机那么将导致数据全部丢失,因此必须存在一种机制将其持久化到硬盘之中。
而主要的两种持久化方式分别是:
- RDB: 为Redis在内存中的所有数据生成快照(二进制序列化)
- AOF: 记录Redis每次对内存数据产生影响的指令
那么分别讲述。
RDB
既然是持久化,自然分主动持久化和被动持久化两种。由上述已知,RDB文件本身是对内存中数据生成快照,如果假设内存中数据很是庞大,那么服务器的IO必然也会遭到很严重的影响。所以为了避免线上产生意外,因此一般我们不会使用被动持久化的功能。
不过值得一说,被动持久化主要根据在多少秒的期限内Redis被操作多少次从而判断是否要生成快照。
其后,生成快照任务也分为两种形式,其一为同步生成,其二为异步生成。即 save 指令与 bgsave。显然前者如果执行将会阻塞Redis的主线程,而后者则是单独开辟一个子线程进行任务。
其实很显然,这个时候也会存在一些问题。由于RDB采用了copy On Write的策略将导致在执行生成快照指令的期间将丢失后来修改的数据,这个是需要注意的。
每次 CopyOnWriteArrayList 进行写入操作的时候,都会将自己的数据去复制一份副本,而写入的操作在副本之上,当修改完毕后再将之前的指针指向副本。这也就意味着,读取和写入之间并不会造成冲突,也就是写入并不会阻塞读取操作。
来自: Java 并发容器与阻塞队列:ConcurrentHashMap / CopyOnWriteArrayList / BlockingQueue..
AOF
与RDB不同,AOF采用的是记录客户端指令日志的方式进行持久化,当重启后使用对应的日志文件重新执行一遍就可以恢复之前的数据。主要使用fsync指令进行异步的写入到日志之中。
其后产生了何时执行fsync指令?这样的问题,Redis向我们提供了三种策略,分别如下:
- always 每次执行对数据产生影响的数据时
- everySec 指令存入缓冲区之中,每隔一秒执行一次
- no 不主动执行持久化
显然,第一种方式虽说它能够保证内存中的数据几乎全部都能被持久化,但也造成了非常频法的IO操作,以致于开销极大。而其二,则是在保证持久化和性能影响之中做出平衡。其三则是根据操作系统对于宕机的处理。
一般我们使用第二种策略,即每隔一秒执行一次fsync指令。
主从复制
我们一直都会说Redis是一个高可用的中间件,那么它主要体现在那里呢?其一是在出现问题时数据尽量少丢失,其二是服务尽量少中断。
而前述的持久化便是让数据尽量的少丢失。但如果我们的Redis仅仅只是一个单节点,其实并不能完全的保证高可用性。因此大部分企业都会再养一个备胎,即除主节点外再备份一个或多个的从节点,这些从节点的数据与主节点相同,以此保证高可用性。不过以此亦可以去实现多个节点的读写分离。
通过名字便可知,主从复制便是将主节点的数据去复制到从节点上。
首先一共有两种方式能够实现:
- 子节点使用 replicaof + 主节点IP + 端口
- 在配置文件中配置
对于复制而言共有以下几个场景:
- 从节点请求主节点上的所有数据,获取全部数据(从节点启动时自动执行)
- 从节点与主节点断连后的恢复
这两个场景分别对应主从复制中的全量复制与增量复制。
全量复制
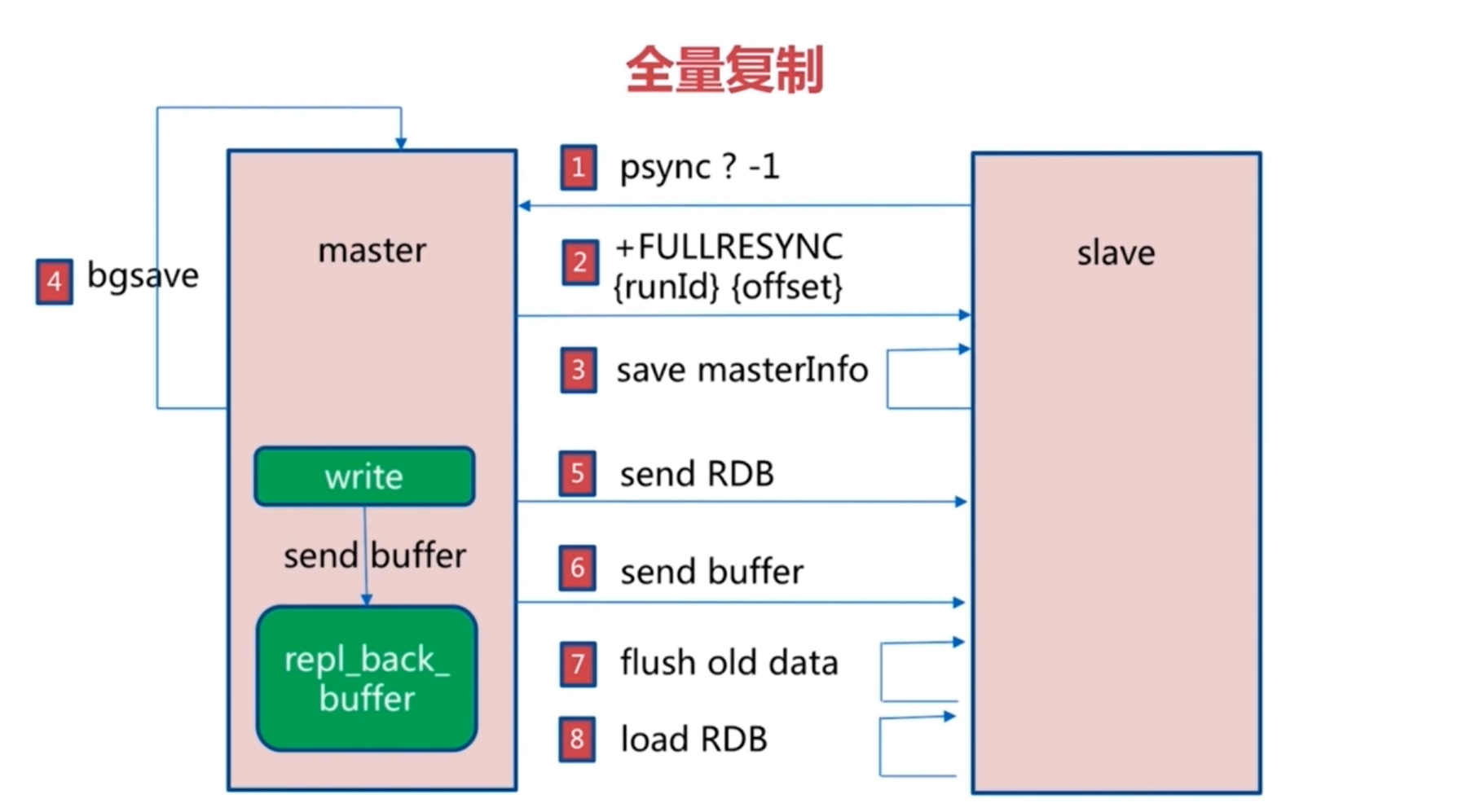
当子节点成功与主节点连接后,子节点会发送psync ? -1,后面的问号与-1分别代表主节点id与当前从节点的数据偏移量两个参数,由于第一次并不知道主节点的id,以及从节点并未获取到主节点的数据也自然没有偏移量。
其后主节点会将自己的id和自己数据的偏移量发送给从节点,让从节点进行存储。其后主节点执行bgsave指令去生成RDB快照,完毕后将快照传输给从节点。
而在生成快照与传输快照期间产生的新指令会存储到repl_backing_buffer之中,自快照传输结束后会将其中数据传递给从节点。
其后从节点清除自身数据后加载RDB文件。自此全量复制的流程便结束,随后主节点与从节点会维护一个长连接,向从节点发送后续更新的数据。
而在向从节点发送前,会先把指令放到repl_backing_buffer之中。
增量复制
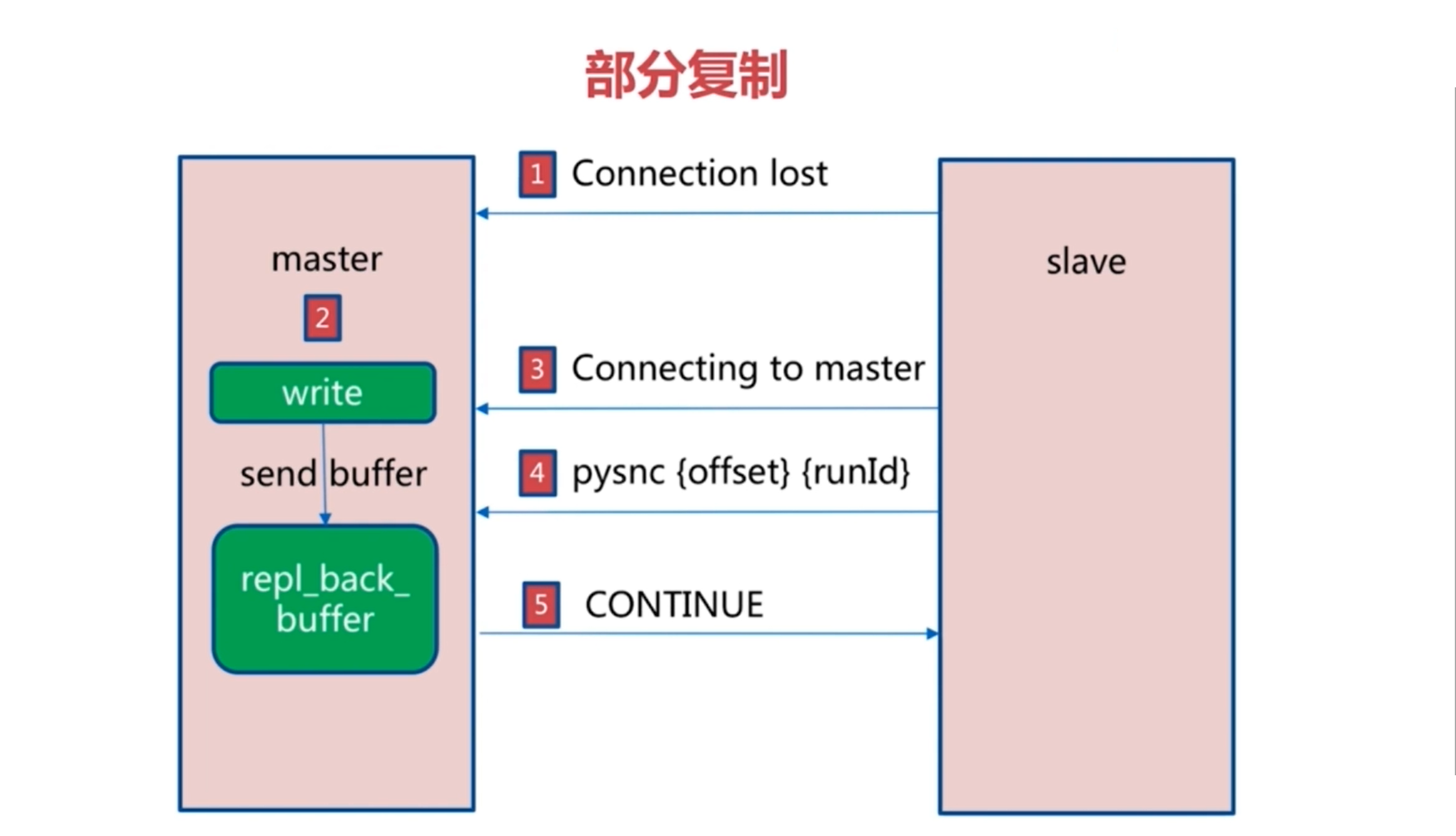
当从节点发现与主节点的连接丢失,且又连接到主节点时,将执行pysnc指令,以当前的偏移值为参数向主节点请求继续进行复制任务。
如果从节点的偏移量仍然处于主节点中的repl_backing_buffer之中,那么将会将偏移值到主节点当前记录之间的数据传递给从节点,以恢复在从节点丢失连接这段时间产生的数据。
倘若buffer中存储的数据早已超过了从节点传递来的偏移值,那么便是意味着从节点将不可能与主节点达成最终一致性。所以当出现这种情况,则会直接执行全量更新以达成数据一致。
主——从——从
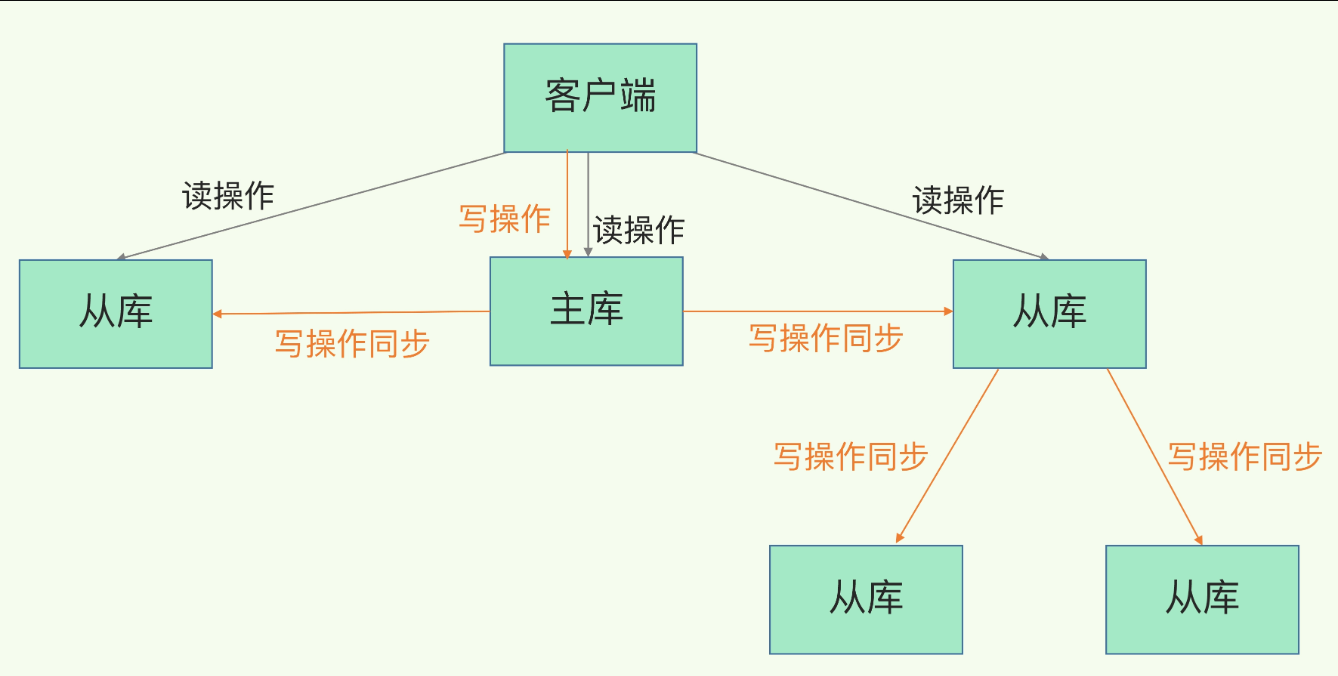
如果从节点数量很多,而且都要与主节点进行全量复制,且要与它们共同维护长连接进行同步,这将给主节点产生很大的性能开销及网络带宽的占用。因此产生了主——从——从模式。即主节点数据传输给某个指定的从节点,其后另外的一些从节点与这个指定的节点建立主从关系。
之后在同步的时候,它们便不是与主节点沟通,压力交给了我们选定的从节点。
笔记留存
