关于多线程
每一个程序都拥有着一个主线程,但在计算机中不可避免地会需要我们的程序同时处理多个任务,此时在基于主线程之外我们就不得不再去开辟一个子线程。而子线程仅是为了某一任务而创建的执行单位,不具备资源,因此损耗会低于开辟进程。
一般情况下,在单核系统中所说的多线程,实际上是指多个任务交错执行,由于执行序列很短,导致交替速度很高,因此给我们多个任务同时执行的假象,这种叫做并发。所以我们的大脑运行速度如果能够一瞬间将多个任务拆分成极小的子任务,那么“左手画方,右手画圆” 是不是就能实现了hhh。
随着计算机硬件的发展,当我们的CPU能够拥有多个核心的时候,此时便拥有了并行(任务同时执行) 的能力。
Java线程状态
共有六种分别是:
- New 创建时
- waiting 等待时
- Sleep 睡眠时
- Blocked 阻塞时
- Terminated 完成时
关于线程池
如果我们的程序会经常需要开辟一个子线程去执行某的任务的时候,如果每次我们都手动的创建与销毁,这将消耗大量的性能。而线程池之所以存在,是因为它会维护某个数量的线程,时刻保持就绪等待任务,不会进行关闭。因此依靠线程池可以解决上述问题。
那么线程池如何设定线程数量?
一般共有三种计算方法。
- CPU计算密集型 最佳线程数为CPU核心的1~2倍
- IO密集型 最佳线程数可以是CPU核心的数倍,因为在“等待回复”的时候线程是可以休息的
- CPU核心 * ( 1 + 平均等待时间 / 平均工作时间)
创建线程池
我们一共有两种创建线程池的方法,其一是通过Executors线程池工厂类进行创建,其二是通过手动创建ThreadPoolExecutor类并配置其线程池。
一般情况下我们最好根据自己的业务需求去设定线程池,而非使用这些工厂方法创建。因为我们可能需要设定符合需求的工作队列,以及任务被拒绝时的策略,又或记录日志。
手动
对于线程池一般有着五个参数。
- corePoolSize 维护线程数
- maximumPoolSize 线程最大数
- unit 最大数线程的维护时间
- workQueue 工作队列
一般情况下当有任务时,会先提交到一个队列之中,随后如果维护的线程有空闲的,那么就将队列中的头任务出队进入线程执行。其后如果维护线程数超过所设置的队列最大长度,且工作队列也满,那么将从工作队列中取出任务单独维护一些线程,数量为设定的线程最大数。
而在此之后,如果扩展到线程最大数后仍无空闲线程,且工作队列亦满,那么将执行拒绝策略。拒绝策略分为以下几种:
- AbortPolicy 丢弃任务并抛出异常
- DiscaredPolicy 直接丢弃
- DIscaredOldestPolicy 丢弃队列中最前面的任务
- CallerRunsPolicy 被拒绝的任务交给提交任务方执行
不过如果想自己设置拒绝策略的话,则不能使用工厂类进行创建了。
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>());
executor.setRejectedExecutionHandler( new ThreadPoolExecutor.AbortPolicy());
而工作队列共有以下几种:
直接交换队列 SynchronousQueue
仅作为临时存放,不具备存储任务功能无界队列 LinkedBlockingQueue
以链式队列存储,队列没有数量限制有界队列 ArrayBlockingQueue
以线性队列存储,队列有数量限制
工厂创建
常用方式 newFixedThreadPool
创建
使用newFixedThreadPool创建的线程池是基于无界队列创建,因此当大量任务阻塞在队列中的话,会造成内存溢出(Out of Memory)。
static ExecutorService executorService = Executors.newFixedThreadPool(线程数量);
执行任务
executorService.submit(() -> {
System.out.println(Thread.currentThread().getName());
});
其他方式
- newCachedThreadPool 没有设置最大的线程数量,线程池使用直接交换队列,因此在运行期间将几乎无限的扩增线程池,但在线程空闲时间达到60秒后会进行回收。它的主要作用我认为应该是在承载所有任务的同时,去主动回收空闲线程,尽可能是降低性能消耗。但创建数量很多地话,也会导致内存溢出。
- newScheduledThreadPool 根据设定的时间定时执行线程池任务
- newSingleThreaded 只拥有一个工作线程,使用无界队列
关闭线程池
// 等待线程池中所有任务执行完毕后终止
executorService.shutdown();
// 立即终止线程池,线程池内所有任务都将被打断且抛出异常,并返回所有队列中未执行的任务
List<Runnable> runnables = executorService.shutdownNow();
// 是否已终止(任务已全部执行完毕或被 shutdownNow 终止)
executorService.isTerminated();
关于ThreadLocal
ThreadLocal的主要目的是在于为每个线程单独去规划一些对象,以及维护仅在当前线程有效的数据。主要解决了在多并发环境下的两个问题。
- 对于一些工具类而言,每个线程需要一个独享的对象,否则将导致线程不安全
- 以当前线程为基础存储数据,避免参数来回传递,类似于js的localstore
针对问题一延申到 SimpleDateFormat 工具类
如下代码所示,通过线程池维护十个线程进行任务。以常理来看,当main方法执行后必然是在70年1月1日8时0分0秒开始向后以次递进1秒,执行1000次。
public class SimpleDateFormatTest {
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
static SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
int I = i;
executorService.submit(() -> {
System.out.println(format.format(new Date(I * 1000)));
});
}
executorService.shutdown();
}
}
但经过测试,发现其中却出现了很多重复值,造成了数据错误。
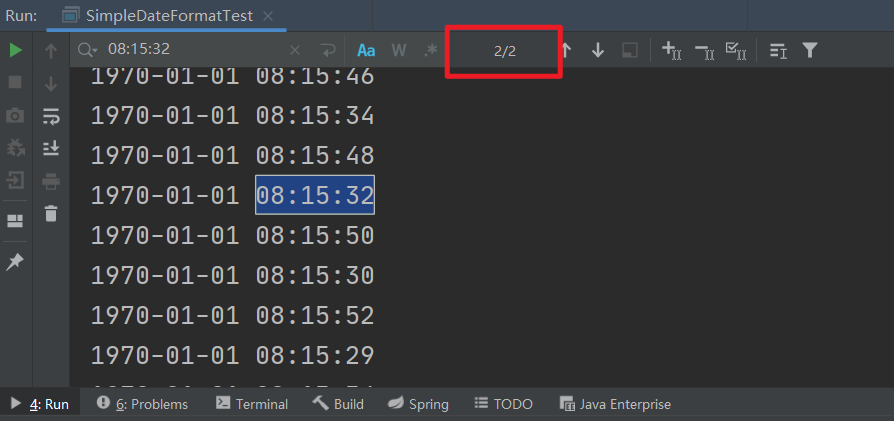
其本质原因在于 SimpleDateformat 在其底层源码中会维护一个名为 calendar 的公共对象,且对其进行设置值与清除值时未对其进行设计并发保护。
当然,对此我们有两个办法。其一是每次任务独自创立一个格式化类。其二,我们可以很轻松的想到使用 synchronized 加锁。但此两者均不如人意。
因此此时便可以引入 ThreadLocal 为线程池的单个线程划分单独的对象。因此程序仅需要维护与线程数同正比的对象情况下,既可实现线程安全。
public static ThreadLocal<SimpleDateFormat> dateFormatThreadLocal =
new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
}
};
还有一种比较简洁的lambda写法。
public static ThreadLocal<SimpleDateFormat> dateFormatThreadLocal =
ThreadLocal.withInitial(
() -> new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
);
其后就可以优化前述代码为下。
executorService.submit(() -> {
System.out.println(
ThreadSafeFormatter
.dateFormatThreadLocal
.get().
format(new Date(I * 1000)));
});
使用 ThreadLocal 存储仅限当前线程的数据
如标题所示, ThreadLocal 会为每个线程维护一个名为 “ThreadLocalMap” 的map,因此我们可以通过它去维护一些需要各个类之间相互传递的数据,如当前会话(线程)下的用户信息。
下述代码与 “针对问题一延申到 SimpleDateFormat 工具类” 一栏中的区别仅在于,前者需要提前使用 initialValue 方法初始化,而后者的使用场景则一般不需要提前初始化。
public static ThreadLocal<User> userContextHolder = new ThreadLocal<>();
public static void main(String[] args) {
userContextHolder.set(new User("张三",10));
User user = userContextHolder.get();
}
关于内存泄漏问题
什么是内存泄漏? 当某个对象不再使用,但它所占用的内存却不能被回收。
而 ThreadLocalMap 在底层之中由于value值存在强引用,因此在key初始值为null的情况下会导致其无法被回收。但 ThreadLocal 会在使用set、remove、rehash 等方法后扫描key为null的值,使其被回收。
但根据我看的课程所说,如果key为null,且ThreadLocal不被使用,也不使用上述方法,且线程长时间不停止,这样就会出现内存泄漏。
不过我有些疑问没有搞明白。因为按照前述所说并没有提供根据key操控 ThreadLocalMap 的函数,且初始化时并不能为其设置key。
其次,我原本在想即使内存泄漏,能存map之中的数据又能有多少呢,但转头一想在高并发场景之下,任何细小问题都可能由于数量庞大而造成严重后果。
因此根据阿里巴巴的Java规约所说,当确定ThreadLocal中存储的对象不再使用的时候,及时的掉用remove方法。